|
Pronunciation (🔊): Zhiheng: /ʤihɛnŋ/, Li: /li/ I am a member of technical staff on the superintelligence team at Microsoft AI, working on multimodal data. Previously, I was a Senior Applied Scientist at Amazon AGI where I led the data efforts for video generation model. Before that, I interned at Meta AI and NEC Labs America. I received my PhD degree in computer science at University of Rochester in 2023 (PhD advisor: Prof. Chenliang Xu) and my bachelor's degree at Wuhan University in 2018. My research interests are data-centric machine learning, computer vision, generative AI, and AI safety. Email: zhiheng.li -at- ieee.org CV / Google Scholar / OpenReview / LinkedIn / Github |
|
|
|

|
technical report / video examples I worked on the training data for Amazon Nova Reel—Amazon's video generation foundation model, including a data-centric approach for camera motion control. |

|
I worked on fairness for Amazon Titan Multimodal models. |
|
|

|
Robik Singh Shrestha, Yang Zou, Qiuyu Chen, Zhiheng Li, Yusheng Xie, Siqi Deng CVPR, 2024 pdf / arxiv We propose FairRAG to mitigate demographic biases of diffusion models (e.g., Stable Diffusion) based on Retrieval Augmented Generation (RAG). |
|
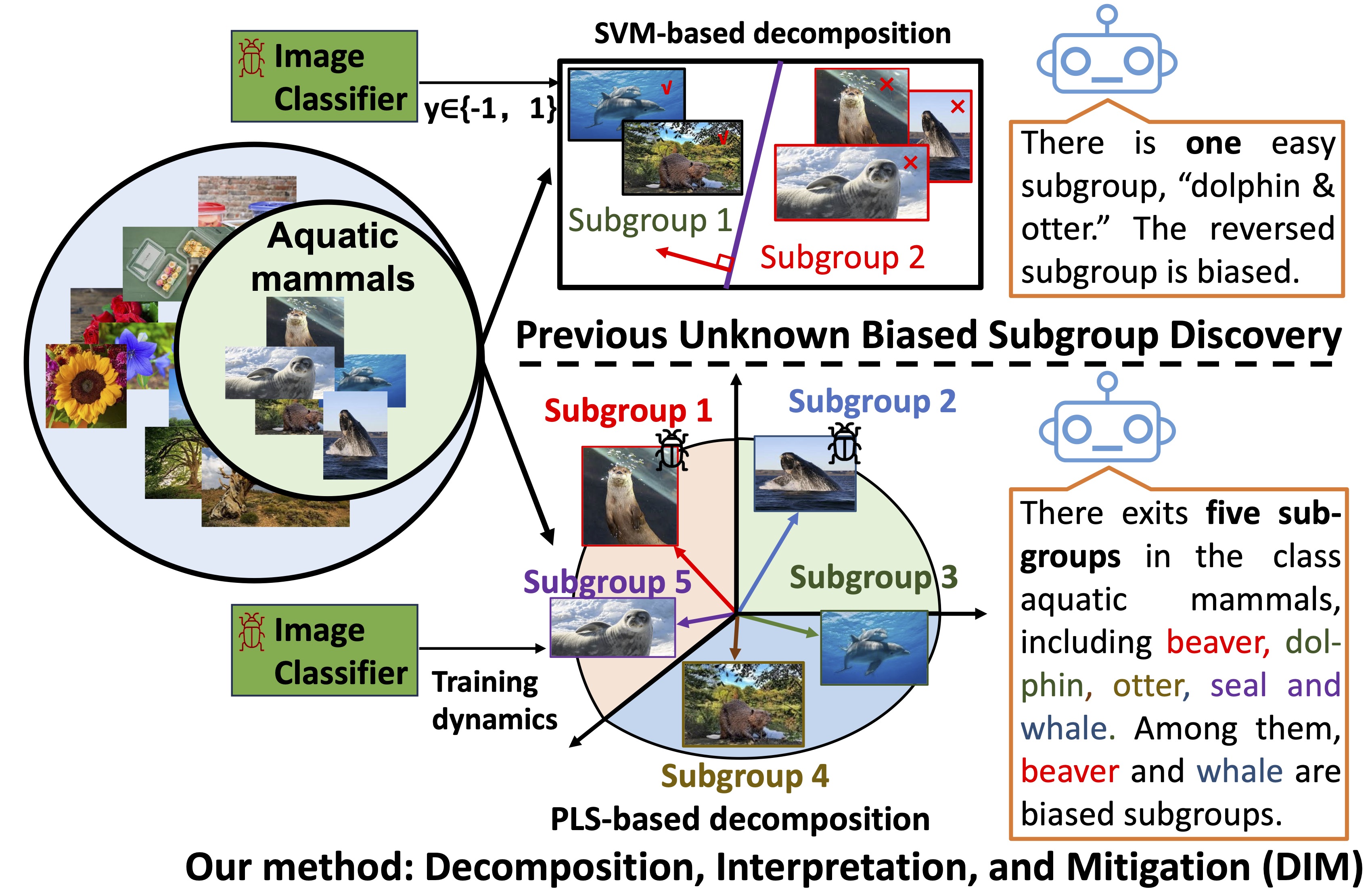
Zeliang Zhang, Mingqian Feng, Zhiheng Li (Project Lead), Chenliang Xu CVPR, 2024 pdf / arxiv / code We proposed a new method to discover multiple biased subgroups based on Partial Least Squares (PLS), which enables dimension reduction guided by useful supervisions from the image classifier. |
|
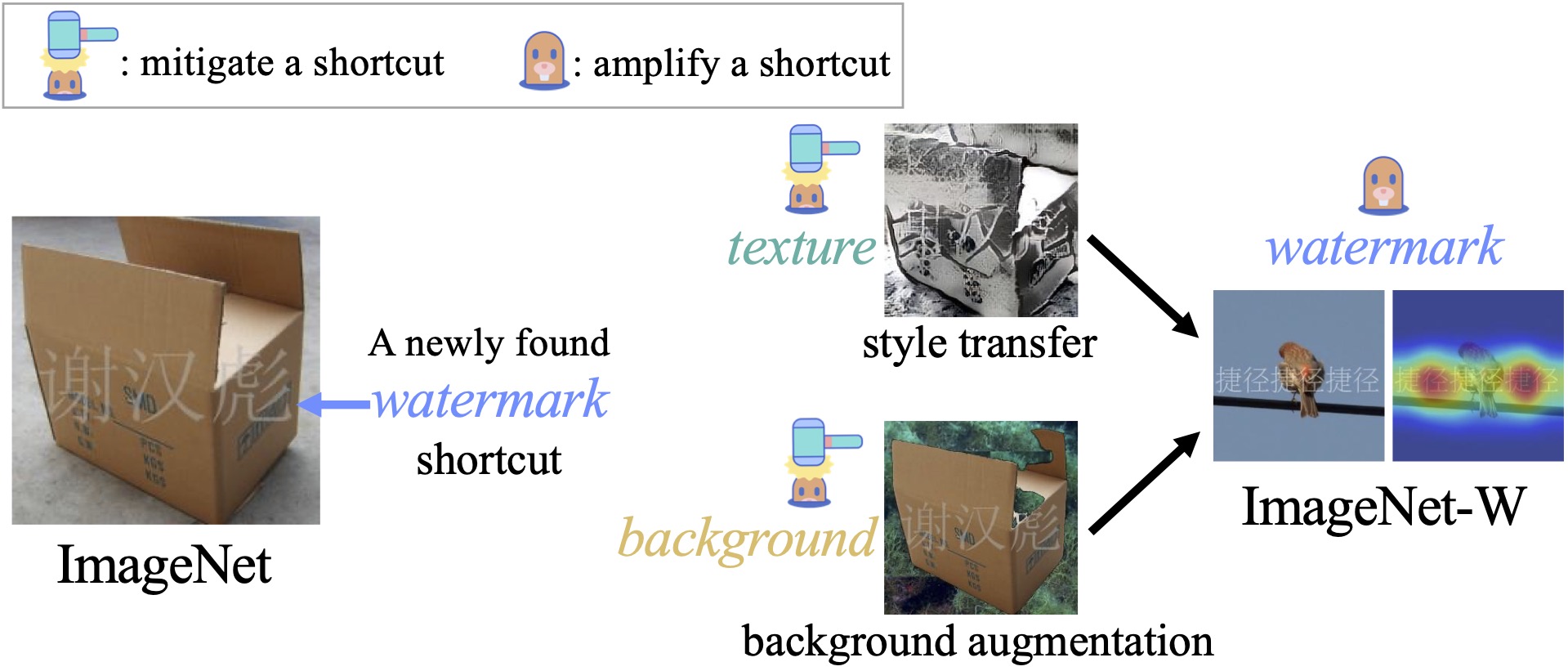
Zhiheng Li, Ivan Evtimov, Albert Gordo, Caner Hazirbas, Tal Hassner, Cristian Canton Ferrer, Chenliang Xu, Mark Ibrahim CVPR, 2023 pdf / bibtex / arxiv / code / video We introduce two new datasets (UrbanCars and ImageNet-W) to study multi-shortcut learning. Especially, ImageNet-W is created based on the newly found watermark shortcut in ImageNet affecting a broad range of vision models, including ResNet, RegNet, ViT, MoCov3, MAE, SEER, SWAG, model soups, and CLIP. Our work surfaces an overlooked challenge in shortcut learning: multi-shortcut mitigation resembles a Whac-A-Mole game, i.e., mitigating one shortcut amplifies others. |
|
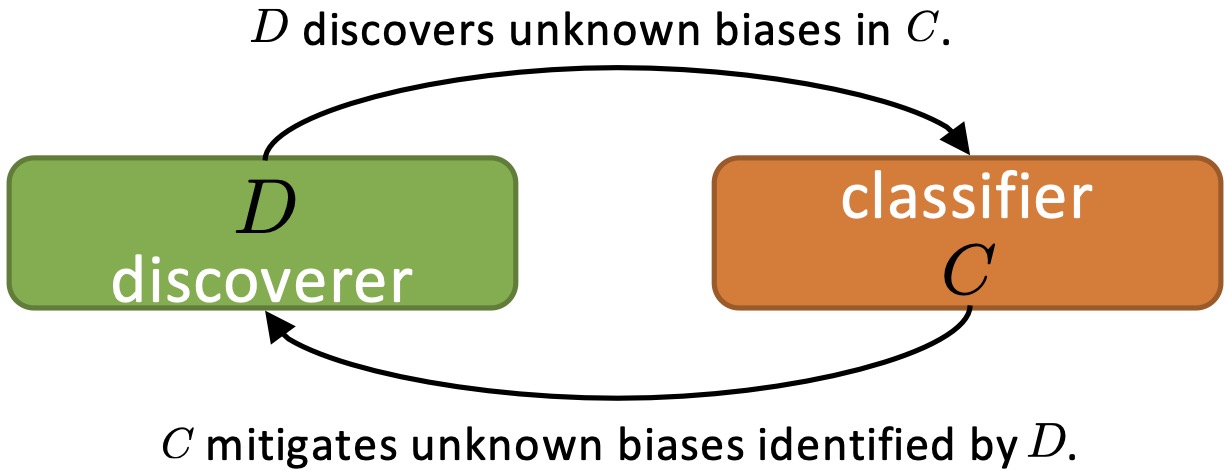
Zhiheng Li, Anthony Hoogs, Chenliang Xu ECCV, 2022 pdf / bibtex / arxiv / code / video We introduce Debiasing Alternate Networks (DebiAN) to discover and mitigate unknown biases of an image classifier. DebiAN trains two networks in an alternate fashion. The discoverer network identifies unknown biases in the classifier. The classifier mitigates biases found by the discoverer. |
|
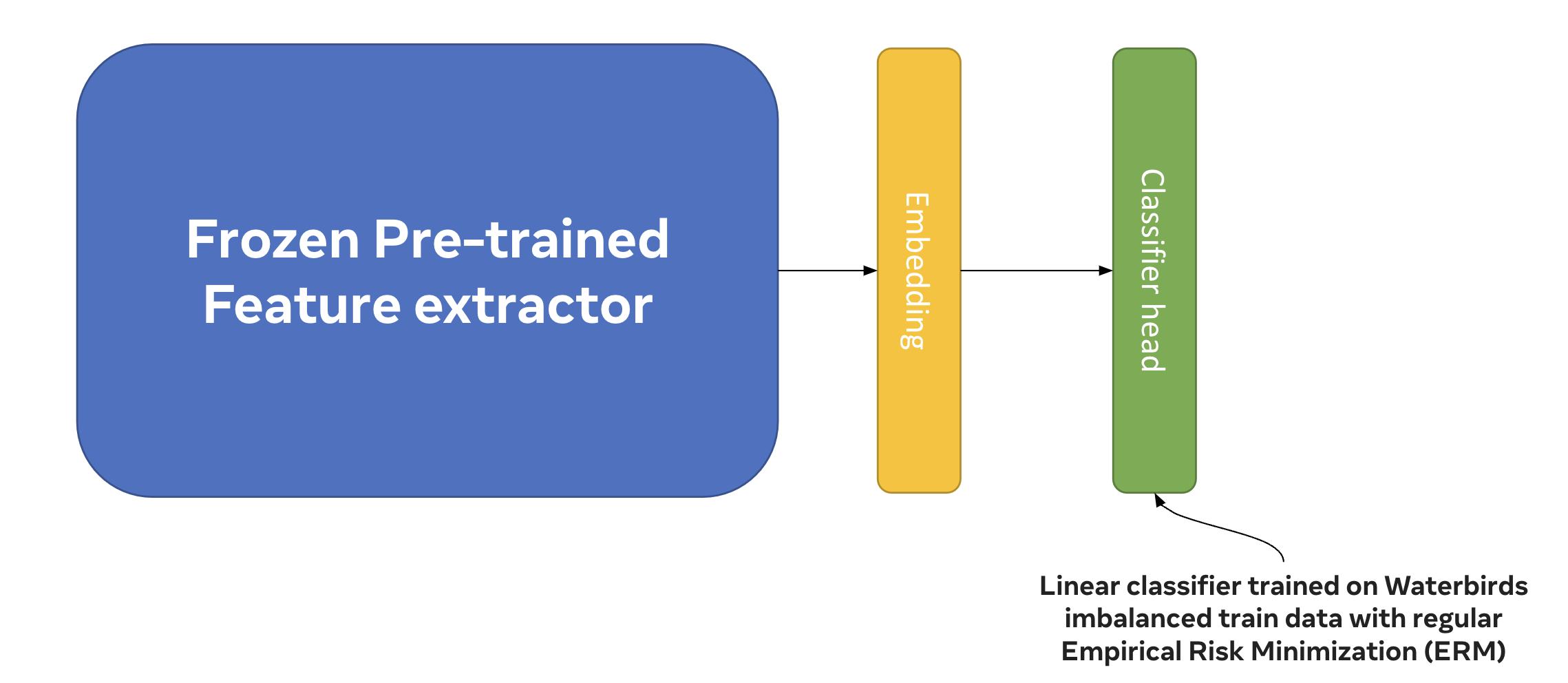
Raghav Mehta, Vítor Albiero, Li Chen, Ivan Evtimov, Tamar Glaser, Zhiheng Li, Tal Hassner ECCV Responsible Computer Vision Workshop, 2022 pdf / bibtex / arxiv Unlike existing approaches (e.g., GroupDRO) focusing on reweighting or rebalancing training data, we show that simply using embeddings from a large pretrained vision model extractor (e.g., SWAG) and training a linear classifier on top of it without training group information achieve state-of-the-art results in combating group shift on Waterbirds. |

|
Zhiheng Li, Martin Renqiang Min, Kai Li, Chenliang Xu CVPR, 2022 pdf / bibtex / arxiv / code / video We introduce a new framework, StyleT2I, to improve the compositionality of text-to-image synthesis, e.g., faithfully synthesizing a face image in “a man wearing lipstick” that is underrepresented in the training data (e.g., due to societal stereotypes). |
|
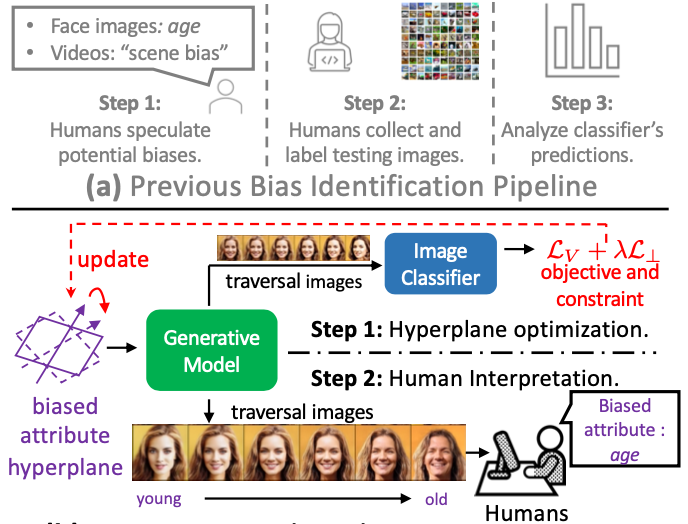
Zhiheng Li, Chenliang Xu ICCV, 2021 pdf / bibtex / arxiv / code / video We study a new problem: discover the unknown bias (i.e., the bias that is out of human's conjecture) of an image classifier. We tackle it by optimizing a hyperplane in generative model's latent space. The semantic meaning of the bias can be interpreted from the variation in the synthesized traversal images based on the optimized latent hyperplane. |
|
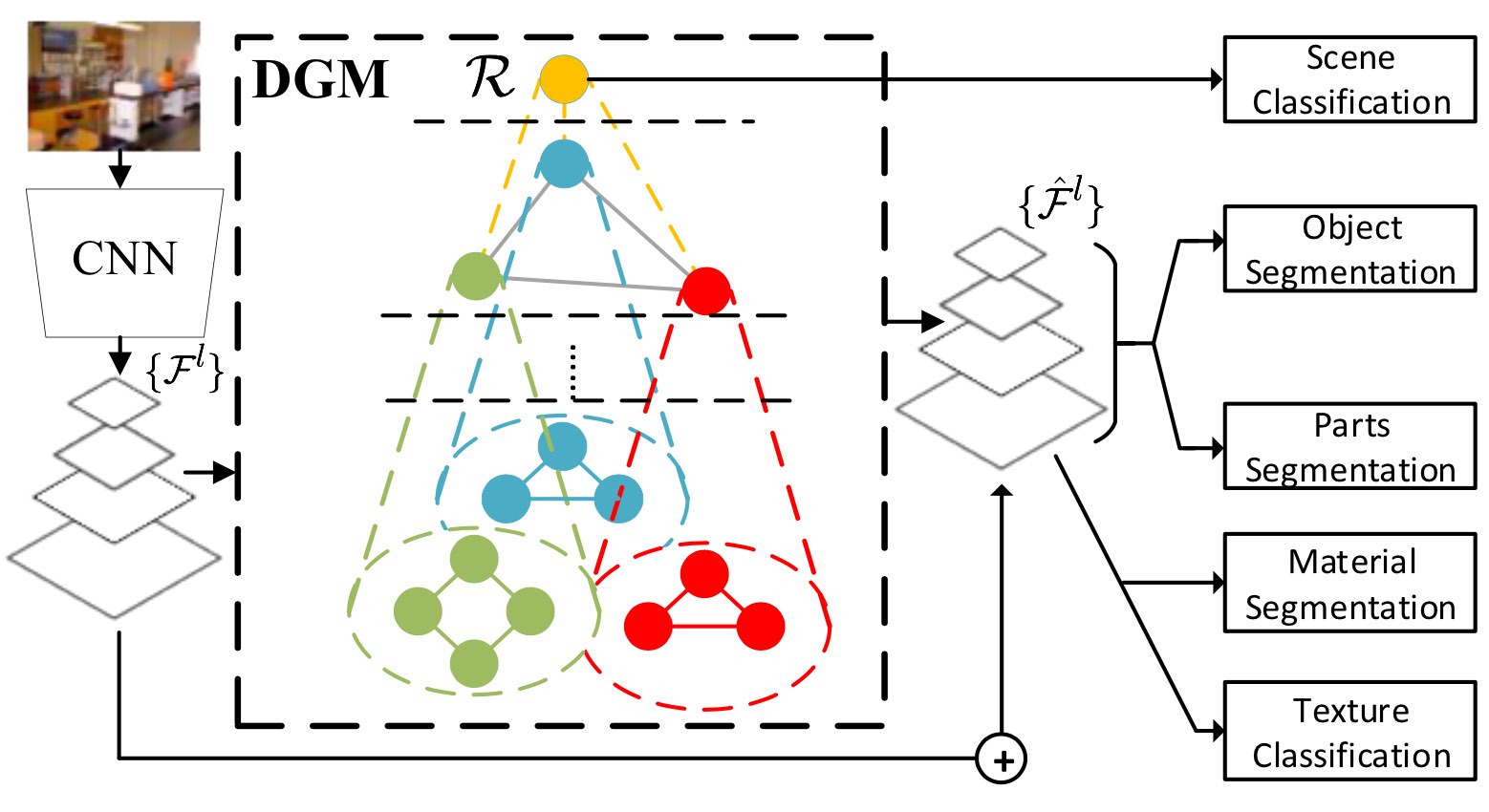
Zhiheng Li, Wenxuan Bao, Jiayang Zheng, Chenliang Xu CVPR, 2020 pdf / bibtex / arxiv We propose DGM, which incorporates the traditional perceptual grouping process into modern CNN architecture for better contextual modeling, interpretability, and a lower computational overhead. |
|
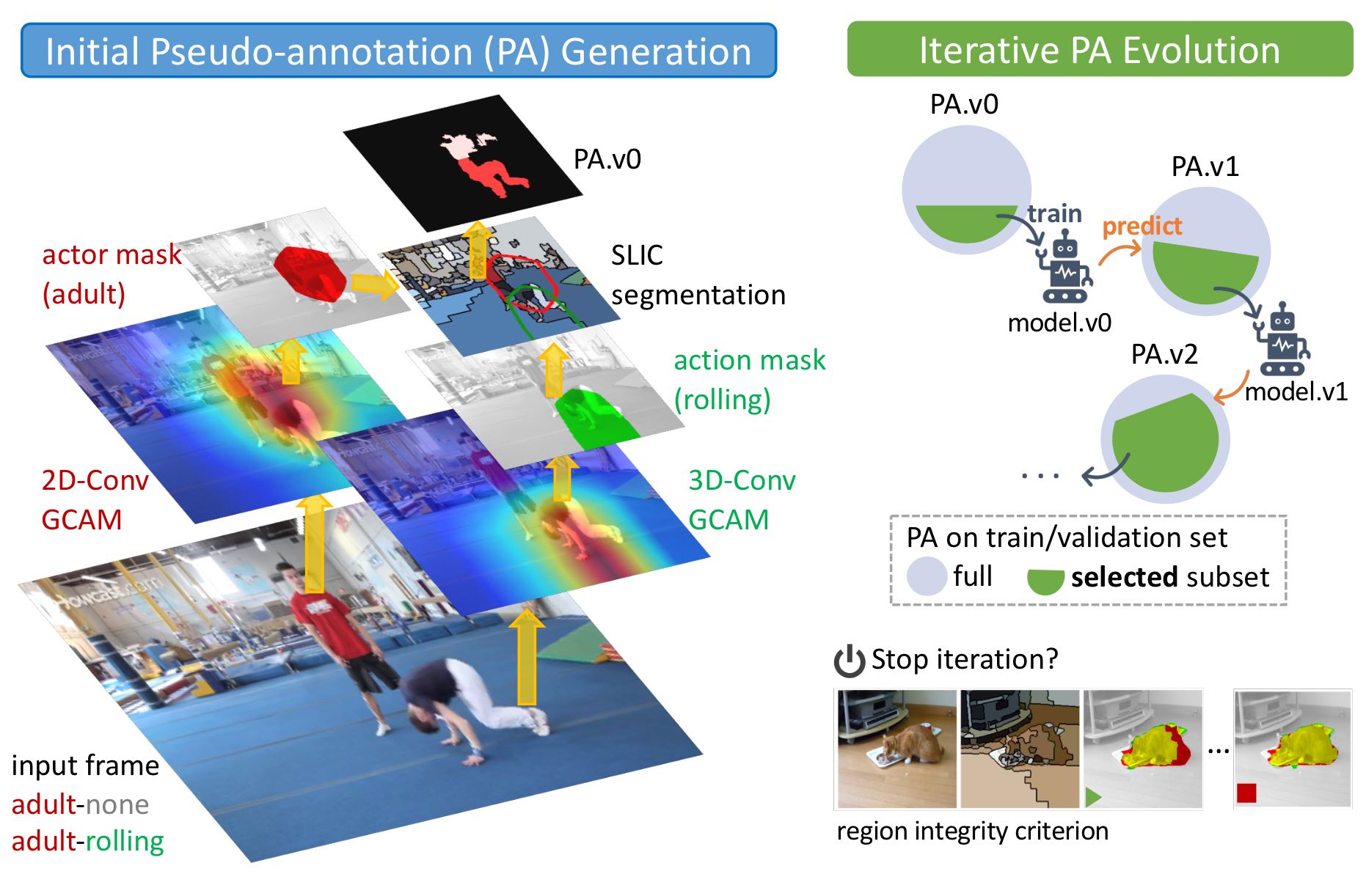
Jie Chen, Zhiheng Li, Ross K Maddox, Jiebo Luo, Chenliang Xu CVPR, 2020 (Oral Presentation) pdf / bibtex / arxiv A novel method to generate and evolve the pseudo-annotations for weakly-supervised video actor-action segmentation task. |
|
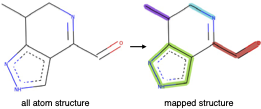
Zhiheng Li, Geemi P. Wellawatte, Maghesree Chakraborty, Heta A. Gandhi, Chenliang Xu, Andrew D. White Chemical Science, 2020 pdf / bibtex / code / dataset / arxiv We train a GNN to predict coarse-grained (CG) molecule, i.e., graph partitioning on the given molecule. We also collect HAM dataset, which provides CG mapping annotations of molecules. |

|
Lele Chen*, Zhiheng Li* (*Equal Contribution), Ross K Maddox, Zhiyao Duan, Chenliang Xu ECCV, 2018 pdf / code / video / bibtex / arxiv Given an audio speech and a lip image of an arbitrary target identity, synthesize lip movements of the target identity saying the speech. |
|
|
 |
Microsoft AI
superintelligence, multimodal team 02/2026 - Present Redmond, WA Member of Technical Staff |
|
Amazon AGI
Vision Skill team 11/2023 - 01/2026 Bellevue, WA Senior Applied Scientist |
|
|
AWS AI Labs
Bedrock Multimodal Responsible AI team 07/2023 - 11/2023 Bellevue, WA Applied Scientist II |
|
|
Meta AI
Responsible AI (Robustness and Safety team) 05/2022 - 12/2022 Seattle, WA Research Intern Mentors: Ivan Evtimov, Mark Ibrahim, Albert Gordo |
|
 |
NEC Labs America
Machine Learning Department 06/2021 - 09/2021 Princeton, NJ Research Intern Mentors: Martin Renqiang Min, Kai Li |
|
|
|
University of Rochester
08/2018 - 07/2023 Rochester, NY Ph.D. in Computer Science Advisor: Chenliang Xu |
|
|
Wuhan University
09/2014 - 06/2018 Wuhan, Hubei, China B.Eng. in Software Engineering |
|
|
| Conference Reviewer: | NeurIPS'20, CVPR'21, ICML'21, ICCV'21, NeurIPS'21, ICLR'22, AAAI'22, CVPR'22, ICML'22, ECCV'22, NeurIPS'22 (top reviewer), CVPR'23, ICML'23, FAccT'23, ICCV'23, NeurIPS'23, ICLR'24, CVPR'24, ICML'24, ECCV'24, ICCV'25 |
|---|---|
| Journal Reviewer: | TMLR, TPAMI, TMM |
| Volunteer: | FAccT'21, ICLR'21 |
|
The template is based on Jon Barron's website.
The Whack-A-Mole icon is created by Flat Icons - Flaticon
The Themis image is created by Vectorportal.com, CC BY
|